
IHybrid Transformer-CNN-Based Attention in Video Turbulence Mitigation (HATM)
IK Lab, a leader in AI-driven computer vision solutions, is proud to announce the presentation of its latest research, “Hybrid Transformer-CNN-Based Attention in Video Turbulence Mitigation (HATM),” at the prestigious ICPR 2024. ICPR (International Conference on Pattern Recognition) is recognized as one of the premier global events in computer vision research.
The study introduces a novel deep learning framework integrating hybrid Transformer and CNN-based attention mechanisms to mitigate turbulence in video sequences. Designed with efficiency in mind, the HATM model significantly enhances image clarity by leveraging advanced attention mechanisms and U-Net architectures. Extensive testing on synthetic and real-world datasets demonstrated superior performance compared to state-of-the-art methods, particularly in improving PSNR and SSIM scores.
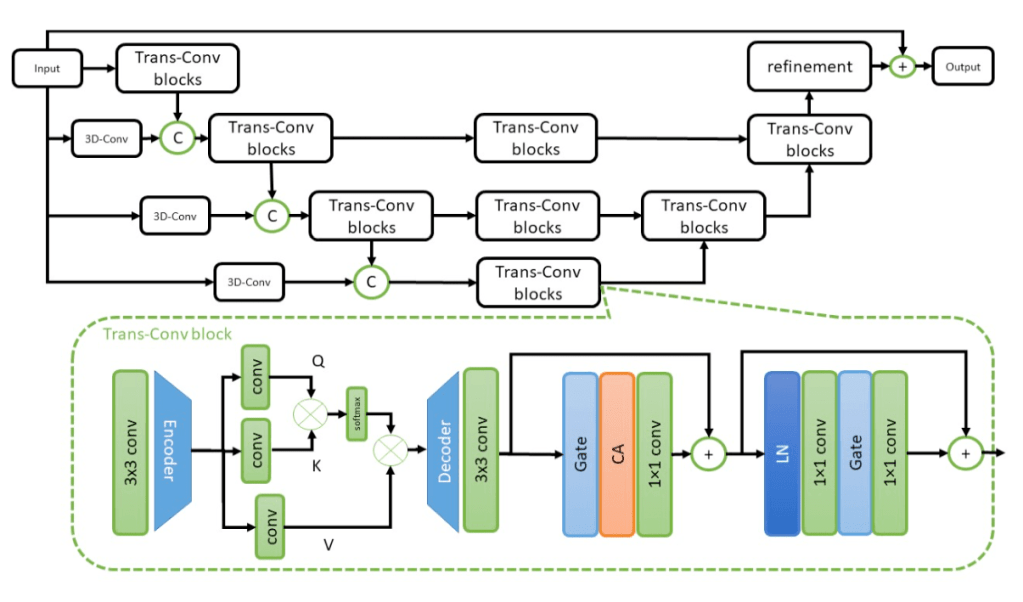
Figure: Structure of the proposed Hybrid Transformer-Convolutional Turbulence Mitigation Model (HATM). CA and LN indicate channel attention and layer normalization, respectively
Dr. IK Hyun Lee, the lead researcher and founder of IK Lab, remarked, “Presenting our work at ICPR underscores IK Lab’s commitment to advancing the frontiers of AI technology. HATM’s success highlights our dedication to solving real-world problems with cutting-edge innovation.”
PDET: Progressive Diversity Expansion Transformer for Cross-Modality Visible-Infrared Person Re-identification
Visible-Infrared Person Re-identification (VI-ReID) plays a crucial role in improving recognition performance under weak-lighting and nighttime conditions, making it a vital research direction in pattern recognition and computer vision. However, existing methods often focus on minimizing image differences between modalities (visible and infrared) to extract reliable features, neglecting the ability to distinguish identities with similar appearances.
To address this issue, we propose a framework called Progressive Diversity Expansion Transformer (PDET), which includes two key components:
1. Diversity Distinguishing Vision Transformer Module (DDViTM): This module generates multiple embedded output vectors for a single input, learning diverse feature representations of pedestrians across modalities. It enhances the system’s ability to differentiate individuals with similar appearances.
2. Cross-Modality Similarity Matching (CMSM) Module: This module improves feature similarity between visible and infrared images. It dynamically adjusts the sequence weights of the two modalities, optimizing training and network efficiency.
We evaluated the PDET framework using the SYSU-MM01 and RegDB datasets, widely recognized public benchmarks for VI-ReID. The results demonstrate that our algorithm achieves promising performance compared to state-of-the-art methods.
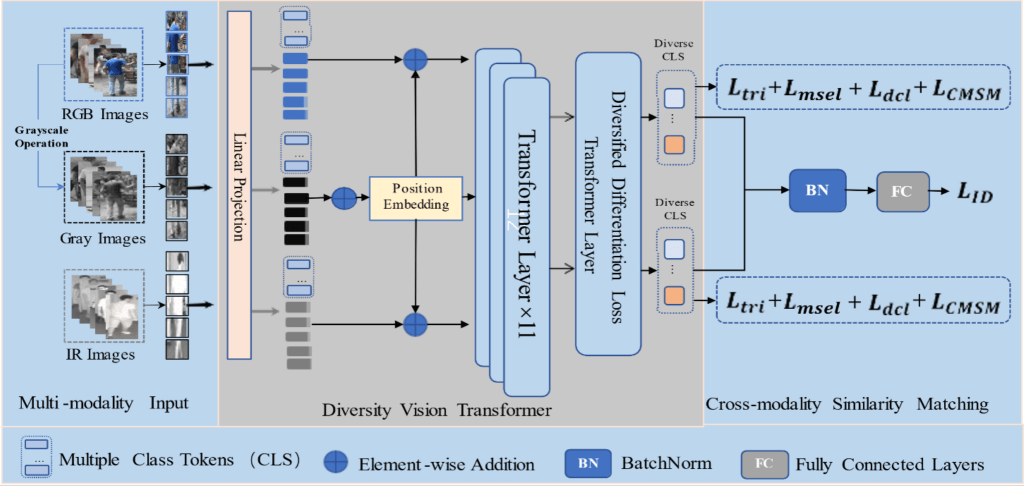
Figure: The left part is the multimodality images input, which includes RGB, Grayscale, and IR (Infrared) images. The middle one is the Diversity Vision Transformer Module with the Multiple Class Tokens for the corresponding modality of the previous part and visual transformation. The loss functions are following at the right part for the framework’s optimization.
IK Lab continues to collaborate with leading academic institutions and industry partners to redefine the limits of AI and machine learning.
For more information, visit our official site or contact us at ihlee@iklab.ai or meet us at ICPR 2024 venue.


Location
Hours
Contact

